Operators
The PostgreSQL case
So, coming back to Postgres now. What would we need to get a persistent, horizontally scalable and possibly also highly available PostgreSQL cluster?
Storage allows us to persist data, and Stateful Sets allow us to maintain identities and thus roles within a cluster, but unfortunately that is not sufficient yet.
Horizontal scalability is challenging to implement. Replication is the crucial pillar of horizontal scalability, and PostgreSQL supports unidirectional replication from Primary to (Hot) Standby (formerly Master-Slave Replication), which is enough for many use-cases where data are more read than written. Bidirectional replication (aka Multi-Master Replication), however, is entirely more complex due to the system being also responsible for resolving any conflicts that occur between concurrent changes.
Thus, we are going to stick with unidirectional replication here: one node for writing data to, and one to several nodes for reading from. What do we need for that?
- First of all, we need to have Pods with an identity and persistent storage each that should be spread over our Kubernetes cluster. That we know how to get easily: StatefulSets and PV/PVC help us out, and podAntiAffinity ensures distributing.
- Then we need to have replication
in place from the primary node to the standby
node(s). Basic, since it’s part of the Postgres configuration stored in a
ConfigMap
with all sensitive data stored in
Secrets
.
- Or not? Easy enough to set up while creating the cluster, but what if a standby node is added a long time later, and in the meantime there are no more sufficient WAL segments on the primary node?
- Either way, we need to support initializing the replication by copying the primary nodes’s data directory to the standby node.
- So we need to have means available of getting these data around. Sidecar containers in a multi-container Pod can achieve getting the backup from any node and applying the restore to the new standby node.
- Then we need means of addressing all standby nodes for balancing read requests over them. A Service will do that. And we need another Service - maybe the headless one for the Stateful Set will suffice - for addressing the primary node.
- In case the primary node fails for whatever reason we need to promote a standby node. A
livenessProbe
helps determining the current state of a Pod, and
adjusting Labels
could trigger actions.
- For triggering appropriate actions we’d need some sort of reconciliation loop: what is the current state of the database cluster, and what is the desired state, make it match, …
- Our application needs to support sending database queries to the correct Service depending on whether they are read-only or might write as well. Yes, there exists middleware that claims to be able to split traffic accordingly, but only to a certain degree and thus of limited use, at the price of increasing complexity. This is beyond the scope of these exercises, however.
Well, the Kubernetes parts are already getting complicated enough. Kubernetes Operators to the rescue.
Operators
Operators are a design pattern made public in a 2016 CoreOS blog post.
Operators implement and automate common activities in a piece of software running inside your Kubernetes cluster, by integrating natively with Kubernetes concepts and APIs. We call this a Kubernetes-native application. With Operators you can stop treating an application as a collection of primitives like Pods, Stateful Sets, Services or ConfigMaps, but instead as a single object that only exposes the knobs that make sense for the application.
The premise of an Operator is to have it be a custom form of Controllers, a core concept of Kubernetes. A controller is basically a software loop that runs continuously on the Kubernetes control plane nodes. In these loops the control logic looks at certain Kubernetes objects of interest. It audits the desired state of these objects, expressed by the user, compares that to what’s currently going on in the cluster and then does anything in its power to reach the desired state.
This declarative model is basically the way a user interacts with Kubernetes. Operators apply this model at the level of entire applications. They are in effect application-specific controllers that may in turn be implemented with more basic objects like Pods, Secrets or PersistentVolumes, but carefully arranged and initialized, specific to the needs of this application. This is possible with the ability to define custom objects, called Custom Resource Definitions (CRD).
In other words: chances are someone already did all the work to integrate a common application using an Operator. Check OperatorHub.io for details.
Exercise - Create a PostgreSQL cluster using an operator
Enough with all this text, let’s test how this works.
The Postgres Operator is already preinstalled in our cluster (via helm, by the way, see Setup instructions above), cf.
kubectl get all --all-namespaces --selector app.kubernetes.io/name=postgres-operator
so let’s see which CRD it provides:
kubectl get crd --selector app.kubernetes.io/name=postgres-operator
NAME CREATED AT
operatorconfigurations.acid.zalan.do 2023-12-01T06:52:34Z
postgresqls.acid.zalan.do 2023-12-01T06:52:35Z
postgresteams.acid.zalan.do 2023-12-01T06:52:35ZThis mimics the standard Kubernetes API resources (cf. kubectl api-resources), indicating who was responsible for its
inception (-> zalan.do) and which of their projects this provides (-> acid, quite fitting
).
Now, let’s put this to use with the following ad-hoc command (yes, execute it all at once):
cat <<.EOF > postgres-via-operator.yaml
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: exercises-minimal-cluster
spec:
teamId: "exercises"
volume:
size: 1Gi
numberOfInstances: 2
users:
matthias:
- superuser
- createdb
another_user: []
databases:
mydb: matthias
preparedDatabases:
another_db: {}
postgresql:
version: "12"
.EOFNote
The name of the database cluster must start with the teamId and -, this stems from a design decision at Zalando.
Apply this config via
kubectl apply -f postgres-via-operator.yaml.
What will this eventually create now? Let check, selecting for a certain label and also displaying another label:
kubectl get all,pvc --selector application=spilo --label-columns spilo-role
NAME READY STATUS RESTARTS AGE SPILO-ROLE
pod/exercises-minimal-cluster-0 1/1 Running 0 82s master
pod/exercises-minimal-cluster-1 1/1 Running 0 38s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SPILO-ROLE
service/exercises-minimal-cluster ClusterIP 10.0.133.171 <none> 5432/TCP 83s master
service/exercises-minimal-cluster-config ClusterIP None <none> <none> 34s
service/exercises-minimal-cluster-repl ClusterIP 10.0.95.236 <none> 5432/TCP 83s replica
NAME READY AGE SPILO-ROLE
statefulset.apps/exercises-minimal-cluster 2/2 82s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE SPILO-ROLE
persistentvolumeclaim/pgdata-exercises-minimal-cluster-0 Bound pvc-0e5c3c2d-4332-4c3a-8096-6a7536b89064 1Gi RWO default 82s
persistentvolumeclaim/pgdata-exercises-minimal-cluster-1 Bound pvc-11a9966b-86f9-473c-9ac9-5762572b514a 1Gi RWO default 38sSo far so expected: a StatefulSet with two Pods, i.e. matching numberOfInstances: 2, each backed by a PVC, and some Services. The Label spilo-role indicates what each will be used for.
No sidecar containers, they are not needed when using this Operator. And in case you are wondering: spilo is Georgian for elephant, matching Postgres’ logo, and the exercises-minimal-cluster-config Service would be be used by the operatorconfigurations.acid.zalan.do CRD.
Exercise - Investigate the Postgres cluster
But does it actually work?
Let’s check by connecting from our old postgresdb Pod:
echo "Use the following password: $(kubectl get secret postgres.exercises-minimal-cluster.credentials.postgresql.acid.zalan.do -o 'jsonpath={.data.password}' | base64 -d)"
kubectl exec -it deployment/postgresdb --container pg-dump -- psql --username postgres --host exercises-minimal-cluster --command '\du' --command '\l'
Password for user postgres:
List of roles
Role name | Attributes
------------+------------------------------------------------------------
admin | Create DB, Cannot login
cron_admin | Cannot login
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS
robot_zmon | Cannot login
standby | Replication
zalandos | Create DB, Cannot login
List of databases
Name | Owner | Encoding | Locale Provider | Collate | Ctype | ICU Locale | ICU Rules | Access privileges
-----------+----------+----------+-----------------+-------------+-------------+------------+-----------+-----------------------
postgres | postgres | UTF8 | libc | en_US.utf-8 | en_US.utf-8 | | |
template0 | postgres | UTF8 | libc | en_US.utf-8 | en_US.utf-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | en_US.utf-8 | en_US.utf-8 | | | =c/postgres +
| | | | | | | | postgres=CTc/postgres
(3 rows)A password for the admin user postgres was autogenerated, it is available in a Secret. The users have been created, with roles as specified (so none for another_user) and their passwords also available via Secrets.
And the databases have been created as well, with the another_db automatically receiving some access roles.
But has replication been set up correctly? Well, first, to make executing the various commands easier, let’s define an alias:
export PGPASS="$(kubectl get secret matthias.exercises-minimal-cluster.credentials.postgresql.acid.zalan.do -o 'jsonpath={.data.password}' | base64 -d)"
alias kubepsql="echo password: $PGPASS; kubectl exec -it deployment/postgresdb --container pg-dump -- psql --username matthias --dbname mydb"Warning
Please use the password printed on the CLI within the following steps!
Now check
kubepsql --host exercises-minimal-cluster --command 'select application_name,backend_start,state,replay_lag from pg_stat_replication'
which should yield something like
Password for user matthias:
application_name | backend_start | state | replay_lag
-----------------------------+-------------------------------+-----------+------------
exercises-minimal-cluster-1 | 2023-12-01 12:47:25.239781+00 | streaming |
(1 row)Now let’s test the replication by feeding data into the primary node and reading it from the standby node. For that check:
kubepsql --host exercises-minimal-cluster --command "create table todo (todo varchar(255) not null primary key); insert into todo values ('testabc')"
kubepsql --host exercises-minimal-cluster-repl --command "select * from todo"
which should yield
Password for user matthias:
todo
---------
testabc
(1 row)Feeding data into the standby node should not work, though:
kubepsql --host exercises-minimal-cluster-repl --command "insert into todo values ('replica')"
should yield
Password for user matthias:
ERROR: cannot execute INSERT in a read-only transaction
command terminated with exit code 1All in all it seems the replication is working.
Exercise - Scale the Postgres cluster
We scale the StatefulSet, right? Wrong. The StatefulSet is just a building block handled by the Operator, so we need to
scale our postgresqls.acid.zalan.do instead:
kubectl edit postgresqls.acid.zalan.do exercises-minimal-cluster
find and adjust the numberOfInstances, or adjust directly via
kubectl patch postgresqls.acid.zalan.do exercises-minimal-cluster --type merge --patch '{"spec":{"numberOfInstances":3}}'
Subsequently the StatefulSet will eventually be scaled up to 3, and some more magic will happen as automatically triggered by the Operator, cf.
kubepsql --host exercises-minimal-cluster --command 'select application_name,backend_start,state,replay_lag from pg_stat_replication'
which will now yield something like
Password for user matthias:
application_name | backend_start | state | replay_lag
-----------------------------+-------------------------------+-----------+-----------------
exercises-minimal-cluster-1 | 2023-12-01 12:47:25.239781+00 | streaming | 00:00:00.134856
exercises-minimal-cluster-2 | 2023-12-01 12:50:48.722062+00 | streaming | 00:00:00.403067
(2 rows)Tip
Please wait until the appropriate number of Pods is created and ready. That should not take long, though.
And we can get our freshly replicated data directly from the new Pod as well:
PODIP=$(kubectl get pod exercises-minimal-cluster-2 -o jsonpath='{.status.podIP}')
kubepsql --host $PODIP --command "select * from todo"which should yield
Password for user matthias:
todo
---------
testabc
(1 row)Have a look - you created something like this:
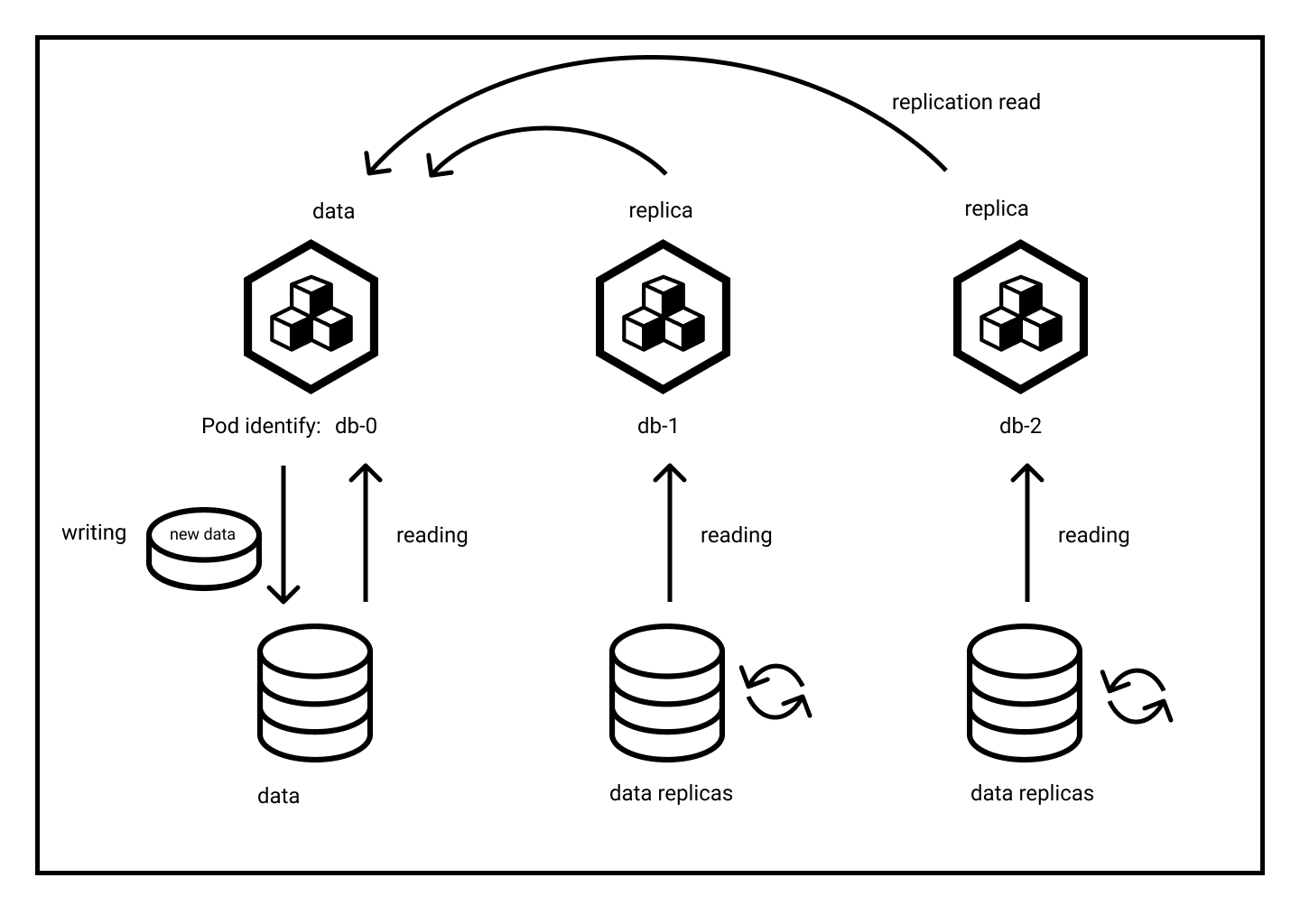
Of course, scaling down works just the same, simply try it. And of course the Postgres Operator provides many more features, including
- backups
- connection pooling
- TLS
- high availability
- cluster cloning
- a web UI
But investigating all of them goes beyond the scope of these exercises, so let’s just drop our database clusters now:
kubectl delete postgresqls.acid.zalan.do exercises-minimal-cluster
and watch how all its resources get deleted in turn:
kubectl get all,pvc --selector application=spilo
Outlook
Well, while the Postgres Operator makes it relatively easy to run a Postgres cluster in Kubernetes, it might make sense to instead rely on DBaaS offers from your cloud provider. The CNCF Blog article “Cloud Neutral Postgres Databases with Kubernetes and CloudNativePG” provides some more insight into this. The same consideration applies to other applications with a certain degree of complexity, like e.g. a Kafka cluster, Elasticsearch, a Spark/Hadoop cluster, or others, depending on your specific needs.
Still, in the course of these exercises we will make use of other Operators as well:
- For Observability
we will utilize
- an Elasticsearch Operator for logs
- a Prometheus Operator for metrics
And those will then be investigated in more detail.
But for now first let’s take a look at another type of Controller, used for Ingress, in the next chapter .