Service Meshes
Background
So, we have started to encapsulate our software components into containers (cf. Applications ), and Kubernetes takes care to distribute and/or scale these containers over our cluster nodes ensuring they are running as defined (cf. Runtime ). Inter-process communication is handled via Services , and we have found means of persisting data (cf. Storage and Stateful Sets ), helpers for getting our applications deployed following best-practices and in an organized manner (cf. Helm and Operators ), and tools for routing external accesses into our cluster (cf. Ingress ).
Each software component of an application is free to be implemented as a microservice using any technology that seems fit for the task (i.e. altogether running a polyglot stack), as long as they are able to communicate with each other in a reliable and secure way. In other words, our microservices are heavily reliant on the network, and that’s just where a Service Mesh now comes into play.
For what we do not have yet are network and security policies and detailed insight into what is going on on the network layer within our cluster. So far each Pod is able to communicate with each Service, and their data exchange is not encrypted in transit. And we have no means of selectively splitting our traffic, e.g. for canary or phased deployments, or to rate-limit (or retry) certain request, and so on. Of course we could now start to implement appropriate measures in our software components, but that introduces considerable overhead in development, so let’s rather utilize a standardized and encompassing set of tools to tackle this on the platform level.
A Service Mesh allows you to separate the business logic of the application from observability, and provides network and security policies. It allows you to connect, secure, and monitor your microservices. As containers abstract away the operating system from the application, a Service Mesh abstracts away how inter-process communications are handled. In general, a Service Mesh layers on top of your Kubernetes infrastructure and is making communications between services over the network safe and reliable:
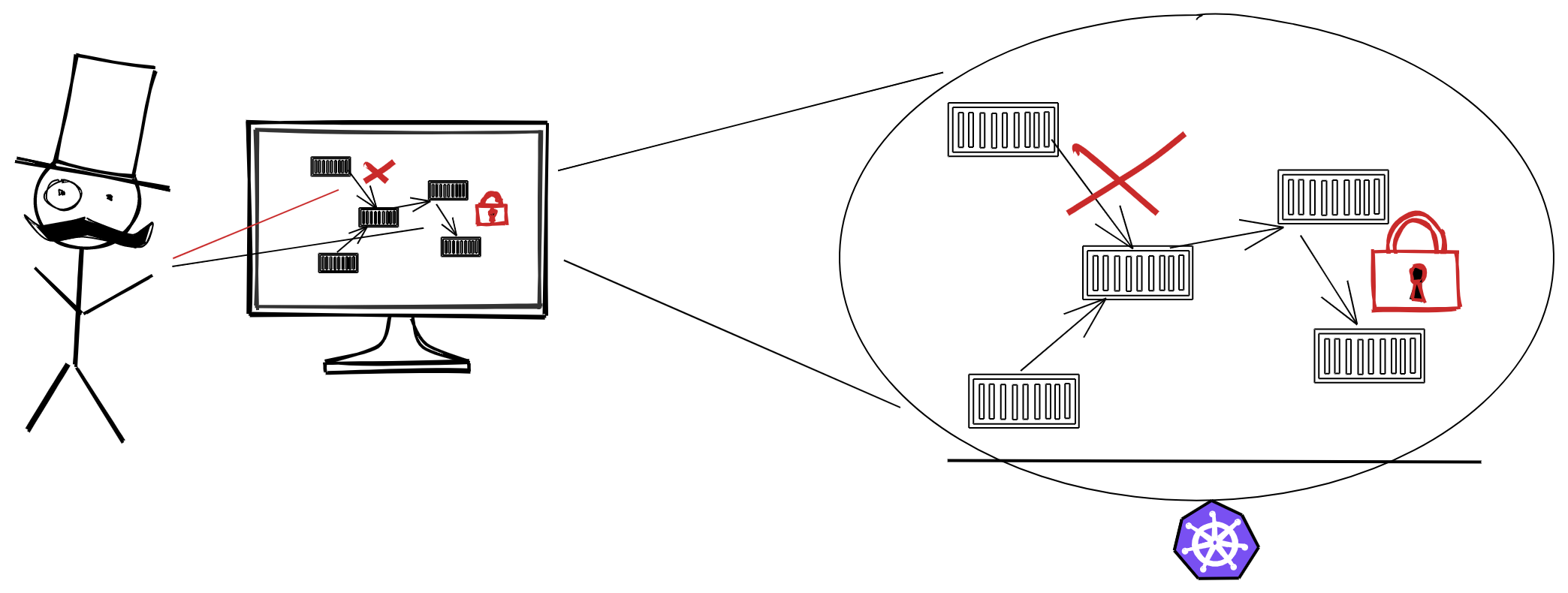
This overall sounds a bit similar to what we have experienced with Ingress , but Ingress focuses on calls from the outside world into the cluster as a whole, whereas a Service Mesh (mostly) deals with the communication inside our cluster. Cf. this blog post for a general introduction.
How does it work?
In a typical Service Mesh, service Deployments are modified to include a dedicated sidecar proxy container, following the ambassador pattern in the context of multi-container Pods. Instead of calling other Services directly over the network, service Deployments are automatically modified to call their local sidecar proxies, which in turn encapsulate the complexities of the service-to-service exchange. The interconnected set of proxies in a service mesh implements what is called a data plane. Strictly speaking, they act as both proxies and reverse proxies, handling both incoming and outgoing calls.
So this
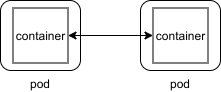
becomes this
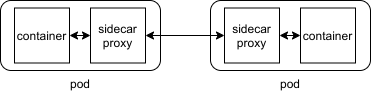
In contrast, the set of APIs and tools used to control proxy behavior across the Service Mesh is referred to as its control plane. The control plane is where users specify policies and configure the data plane as a whole: it’s a set of components that provide whatever machinery the data plane needs to act in a coordinated fashion, including service discovery, TLS certificate issuing, metrics aggregation, and so on. The data plane calls the control plane to inform its behavior; the control plane in turn provides an API to allow the user to modify and inspect the behavior of the data plane as a whole:
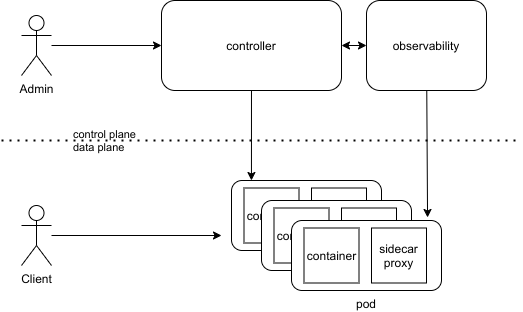
Both, a data plane and a control plane are needed to implement a Service Mesh.
The process of adding sidecars to deployment artifacts and registering them with the Service Mesh control plane is called sidecar injection. All common Service Mesh implementations support manual and automatic sidecar injection.
And while at the first glance it might seem troubling to introduce two additional nodes into each inter-process communication, each increasing latency and consuming cluster resources, and also spending resources for the control plane, it does have its merits as we will see later on.
However, it should be noted that there also exist some approaches to improve that situation, with Sidecar-less setups available in Istio and Cilium .
Implementations
A Service Mesh is not automatically part of a Kubernetes cluster. To choose the implementation that best fits your cluster might be a difficult task, as there are several available, some more focused in their scope and thus easier to deploy and incurring a lower overhead (e.g. Linkerd), some more general in their approach and thus more featureful but with quite some resource demands (e.g. Istio), and some are offered by specific cloud service providers (e.g. AWS App Mesh or Microsoft’s Open Service Mesh (OSM)) or rooted in a specific ecosystem (e.g. HashiCorp’s Consul Connect). Confer to this overview and to these Selection Criteria for more details and the latest CNCF survey for their relative popularity.
And you may deploy any number of Service Meshes within a cluster and add resource annotations or labels for selecting the desired one ad-hoc, or even install and configure them each to only serve a specific namespace, allowing you to always pick the best for the task at hand, of course at the price of additional complexity.
While the value of the service mesh may be compelling, one of the fundamental questions any would-be adopter must ask is: what’s the cost? Cost comes in many forms, not the least of which is the human cost of learning any new technology, but also the resource cost and performance impact of the Service Mesh at scale. Generally they only incur an acceptable overhead at regular operating conditions, when compared to bare metal, but there are considerable differences. For instance, see Benchmarking Linkerd and Istio .
In the course of these exercises we will now cover the two most-common Service Mesh implementations that don’t need external supporting infrastructure:
Feel free to check either of them. However, if you choose to check them both best follow the listed order.
Role-based access control (RBAC)
Either way, as all these implementations affect the whole Kubernetes cluster, we will need to grant you additional access privileges for the following exercises. So beware that you won’t be restricted to your individual namespace anymore from now on but will have full administrative privileges instead.
With that in mind you might want to revisit spots where previously lack of access privileges might have stopped you from proceeding: