Storage
Statefulness
The last scenario in the section Runtime with the failing database also uncovered another problem - the handling of state.
With the help of liveness and readiness probe it is possible to make the application more resilient when it comes to dealing with backend outages. However it does not protect the database losing its state when the container crashes.
Right now the database is being deployed using a construct of Deployment and ReplicaSet objects. However this construct expects a stateless application workload. When the replicas are increased no state is shared between them, hence this will lead to unwanted scenarios even if the replicas are bigger than 1. Which ones in particular?
To address this Kubernetes both provides means of claiming persistent storage, and has a concept of StatefulSets. They are also running multiple pods, but separate between a stateful and stateless part. The stateless part (e.g. the db logic) can be replicated while the state (the actual data) is being shared between them.
This leaves the open question how this shared data should be handled and where it will be persisted. So let’s start with the storage part.
Exercise - Create a PersistentVolumeClaim
A PersistentVolume (PV) is a piece of storage that is added as a volume in the cluster. It can be provisioned by an administrator or dynamically using Storage Classes, with details depending on the cloud provider used. In order to mount an app to a PersistentVolume, you need to have a PersistentVolumeClaim (PVC), which is a request for storage by a user and consumes PV resources.
Before starting to allocate this it might make sense to change the kubectl watch command window. Add the resources PersistentVolumes and PersistentVolumeClaims (you can also take out a few others like configmaps and secrets).
Full list:
watch -n1 kubectl get deployment,replicaset,pod,svc,configmaps,secrets,pvc,pv
The code for a simple version of such a claim looks like this:
cat postgres-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-db-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiYou have that file already checked-out, so now just apply it:
kubectl apply -f postgres-pvc.yaml
Milestone: K8S/STORAGE/POSTGRES-PVC
If you check its state you will see the claim in pending. Don’t worry, this will change once you continue with the next exercise:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/postgres-db-data Pending default 2sAs you can see the STORAGECLASS is listed as default. Well, we haven’t specified any StorageClass, so it makes sense the default one was taken. But in a hosting context there might be several StorageClasses available to choose from depending on your needs: expensive high speed storage, slow cold storage, highly available storage, … And of course it is up to the hosting provider to decide what option they define as default.
This construct can now be used and consumed by our postgresdb deployment.
Exercise - Deploy Postgres backed by PVC
First let’s adjust the deployment of the deployed database, which will recreate its pods.
The todobackend should be able to cope with this for a little while ;-)
The yaml looks very similar to what we had before except for the specification of storage objects as follows:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgresdb
spec:
replicas: 1
selector:
matchLabels:
app: postgresdb
strategy:
type: Recreate
rollingUpdate: null
template:
metadata:
labels:
app: postgresdb
tier: database
spec:
volumes:
- name: db-data
persistentVolumeClaim:
claimName: postgres-db-data
containers:
- image: postgres
name: postgresdb
env:
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-security
key: db.user.name
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: db-security
key: db.user.password
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgres-config
key: postgres.db.name
volumeMounts:
- name: db-data
mountPath: /var/lib/postgresql/data
subPath: postgresdb
- image: postgres
name: pg-dump
command:
- bash
- -c
- while sleep 1h; do pg_dump --host=127.0.0.1 --username=$POSTGRES_USER --dbname=$POSTGRES_DB --file=/pg_dump/$(date +%s).sql; done
env:
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: db-security
key: db.user.name
- name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: postgres-config
key: postgres.db.name
volumeMounts:
- name: db-data
mountPath: /pg_dump
subPath: pg-dumpBy the way, while we are at it we also create a second container within the Pod, sharing access to the Persistent Volume and the localhost networking of the Pod, for really simple backup purposes. This is called sidecar pattern in the context of multi-container pods: next to the container doing the main work we have a small container running for a really specific purpose, like here pulling backups, or possibly regularly pulling contents from a git repository that will then be served by a webserver from the main container, allowing for a simple git push-to-deploy workflow, or possibly checking whether a configuration mapped into the Pod via a ConfigMap - like we did in Reverse Proxy with Nginx - has changed and if so triggering a reload of the main application. See further below to check how this will be reflected in our Pod view.
We will meet another multi-container pattern called ambassador pattern which deals with networking issues when investigating Service Meshes later on.
Anyway, for now just save the above listing to a new file postgres-storage.yaml and apply it:
kubectl apply -f postgres-storage.yaml
Milestone: K8S/STORAGE/POSTGRES-STORAGE
Yes, the name of the YAML files does not matter at all. It’s the contents that count, and as you can see above we now simply overwrite the definition for our postgresdb Deployment, now making the PVC postgres-db-data available to our Pods referenced by the name db-data and then mounting subpaths of that shared volume to where we want to persist data, i.e. the PostgreSQL data storage directory and the place where the crude loop dumps backups.
After applying the cluster will allocate a persistent volume and bind it.
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/postgres-db-data Bound pvc-0c62b293-6a0e-11ea-a995-8e7e16623fe7 1Gi RWO default 2m5s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-0c62b293-6a0e-11ea-a995-8e7e16623fe7 1Gi RWO Delete Bound default/postgres-db-data default 112sPlease note that you might see more than just your own Persistent Volume. These PV are not bound to a specific Namespace, only the Persistent Volume Claims are, so kubectl will display all PV that exist. The CLAIM column will indicate to which Namespace those each belong, though.
After a little while the new pod is up and running, using the storage location of the volume claim (remember, you can easily fill out these placeholders in the following command using TAB-completion):
kubectl describe pod postgresdb-<ReplicaSetId>-<PodId> | grep -C 1 db-data
Mounts:
/var/lib/postgresql/data from db-data (rw,path="postgresdb")
/var/run/secrets/kubernetes.io/serviceaccount from default-token-29xtm (ro)
--
Mounts:
/pg_dump from db-data (rw,path="pg-dump")
/var/run/secrets/kubernetes.io/serviceaccount from default-token-29xtm (ro)
--
Volumes:
db-data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: postgres-db-data
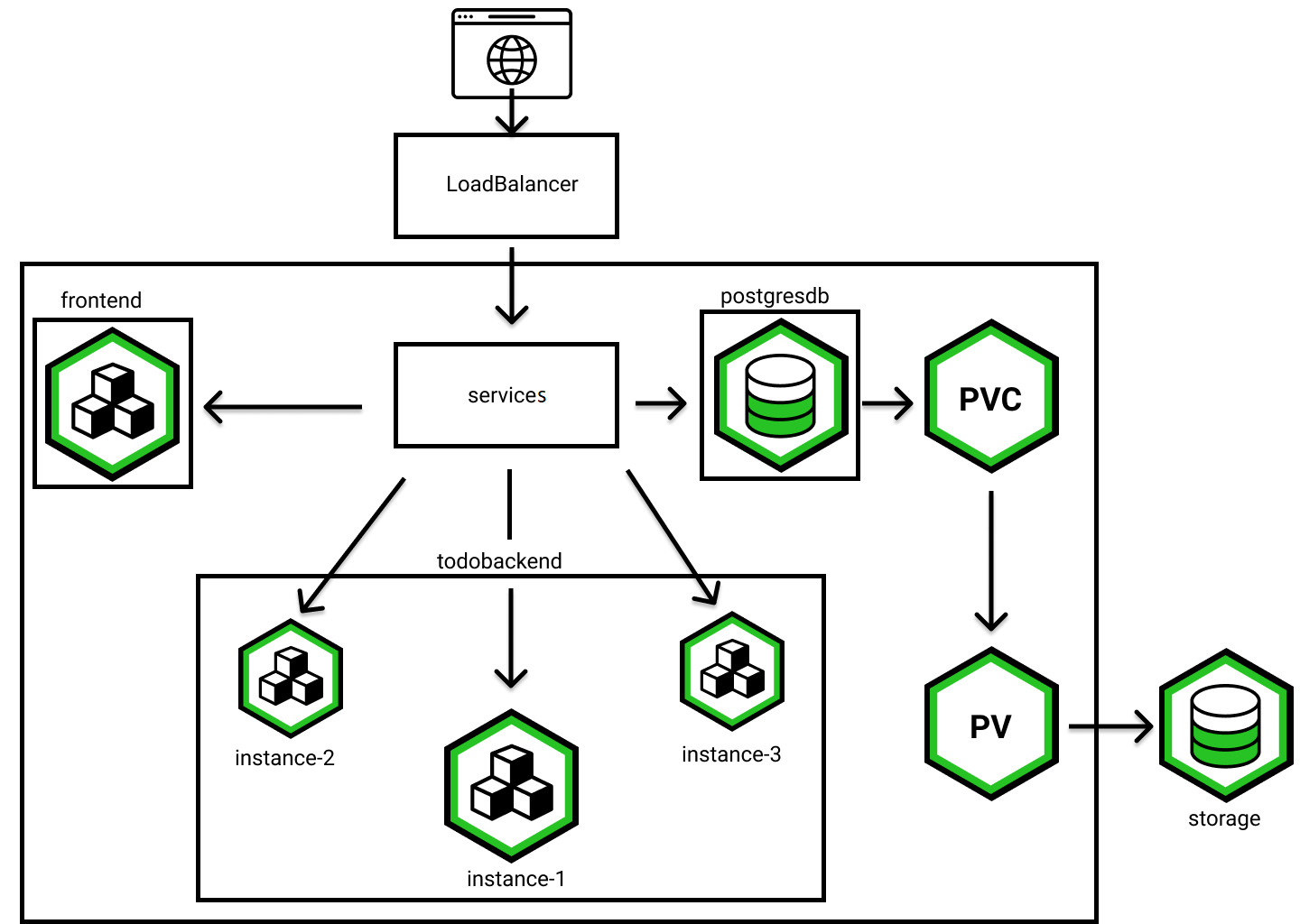
ReadOnly: falseVisualized you could imagine it like this:
Exercise - Crash the database again
Add a few “todos” to the application (either through the UI - manually or via curl - or via curl through the backend)
curl --data toDo=NEW_TODO <LoadBalancer-IP-todoui>:8090/ # no output
curl -X POST <LoadBalancer-IP-todobackend>:8080/todos/NEW_TODO; echo
curl -X POST 20.82.83.63:8080/todos/NEW_TODO; echo
added NEW_TODOMake sure you have at least one before you proceed.
curl 20.82.83.63:8080/todos/; echo
["NEW_TODO"]For checking that we could alternatively access the database contents directly using psql via either container (we do not need to provide a password as the database trusts all connections via local socket or local connection):
export PSQL='psql --username=$POSTGRES_USER --dbname=$POSTGRES_DB --command="select * from todo" --tuples-only'
kubectl exec deployment/postgresdb --container postgresdb -- sh -c "$PSQL"
kubectl exec deployment/postgresdb --container pg-dump -- sh -c "$PSQL --host=127.0.0.1"Either should yield
NEW_TODOAfter that kill the instance
kubectl delete pod postgresdb-<ReplicaSetId>-<PodId>
Wait a while and watch the components resolve the issue. If your todobackend pod is hanging in a CrashLoopBackOff state for too long, you might just delete it as well to speed up progress.
kubectl delete pod todobackend-<ReplicaSetId>-<PodId>
Whenever the application is in full healthy state again like this …
NAME READY STATUS RESTARTS AGE
pod/postgresdb-7c6fcb9d77-5pggt 2/2 Running 0 68s
pod/todobackend-5489d6c5c-55xdj 1/1 Running 2 (3m16s ago) 13m
pod/todobackend-5489d6c5c-575k6 1/1 Running 2 (3m16s ago) 12m
pod/todobackend-5489d6c5c-bb8k6 1/1 Running 2 (3m16s ago) 12m
pod/todoui-ffdd8c6f5-hhhzf 1/1 Running 0 28m(Notice the READY 2/2 for the postgresdb Pod: we have two containers running and ready now.)
List all todos and check if the state has survived the db crash:
curl 20.82.83.63:8080/todos/; echo
["NEW_TODO"]You could even try deleting the full deployment and recreating it from scratch, and all the data will still be present:
kubectl delete deployment postgresdb
Wait a bit until all old postgresdb pods will have terminated, and then:
kubectl apply -f postgres-storage.yaml
How come? Well, the storage had been completely decoupled from the execution layer, so it will persist even when the deployment is deleted. And the deployment will find the storage again via the PVC it references.
Milestone: K8S/STORAGE/POSTGRES-CRASH
Exercise - Handling database contents
Now that we have persistent storage for our postgresdb, let’s consider how we feed data into it. Of course we could do so via the todoui, or we could feed it via curl to the todobackend as we had done above:
curl --data toDo=NEW_TODO <LoadBalancer-IP-todoui>:8090/ # no output
curl -X POST <LoadBalancer-IP-todobackend>:8080/todos/NEW_TODO; echo
And of course we could run kubectl exec deployment/postgresdb --container postgresdb -- sh -c 'psql ... again to feed
data directly into the database.
But all these methods might be slightly problematic when we have a high amount of data to feed and possibly high latency to our endpoints. It would be way better to do some sort of bulk import of data, possibly running directly in the cluster. Well, that sounds like a job for - ahem - Kubernetes Jobs.
First let’s create some data in a file importdata.csv containing what we want to enter into the todo list, e.g. using
the following ad-hoc command (yes, execute it all at once):
cat <<.EOF > importdata.csv
Feed the cat
Really feed the cat
Clean attic
Procrastinate
.EOF(yes, those are not really comma-separated values as we only have a single entry per line, just like the entries get stored in the database)
and make that data available to Kubernetes in form of a ConfigMap:
kubectl create configmap postgresdb-importdata --from-file importdata=importdata.csv
Milestone: K8S/STORAGE/POSTGRES-IMPORTDATA
The data is available now for consumption:
kubectl describe configmaps postgresdb-importdata
[...]
importdata:
----
Feed the cat
Really feed the cat
Clean attic
Procrastinate
[...]And we have prepared a suitable Job template for you to fill out:
nano postgres-import.yaml
This yaml file requires some editing. Please fill in the spaces, all the spaces, (------) with the suitable content, in order to create a Job for the database. Try to fill out yourself or look at the solution below.
After completion apply it:
kubectl apply -f postgres-import.yaml
Milestone: K8S/STORAGE/POSTGRES-IMPORT
And after a few seconds checks its description:
kubectl describe job postgresdb-import | tail -n 4
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 5s job-controller Created pod: postgresdb-import-9tmzj
Normal Completed 1s job-controller Job completedwhich is just in line with
kubectl get jobs
NAME COMPLETIONS DURATION AGE
postgresdb-import 1/1 5s 44sand
kubectl get pods
NAME READY STATUS RESTARTS AGE
postgresdb-7c6fcb9d77-5pggt 2/2 Running 0 3m53s
postgresdb-import-9tmzj 0/1 Completed 0 57s
todobackend-5489d6c5c-55xdj 1/1 Running 2 (6m1s ago) 15m
todobackend-5489d6c5c-575k6 1/1 Running 2 (6m1s ago) 15m
todobackend-5489d6c5c-bb8k6 1/1 Running 2 (6m1s ago) 15m
todoui-ffdd8c6f5-hhhzf 1/1 Running 0 31mNote the READY: 0/1 and STATUS: Completed. Sounds good, but what did the job do?
kubectl logs job/postgresdb-import
COPY 4OK, apparently it copied 4 entries, but are they really there? Let’s check via todobackend (or via todoui, or directly in the database):
curl <LoadBalancer-IP-todobackend>:8080/todos/; echo
e.g.
curl 20.82.83.63:8080/todos/; echo
["NEW_TODO","Feed the cat","Really feed the cat","Clean attic","Procrastinate"]Looking good. The Job itself and the Pod it created will still linger around until the ttlSecondsAfterFinished: 3600 is met, i.e. for one hour, and only then be deleted, which should be plenty of time for us to check its logs, either from the Job resource or directly from the Pod it created. Or we could delete them manually via
kubectl delete job postgresdb-import
Such Kubernetes Jobs could also be used e.g. to apply DB migrations during a deployment or - generally speaking - for any task that should be run only once and not continuously. There are also means to control Job concurrency when working with a bigger set of work items, e.g. for handling a work queue, and means for executing Jobs repeatedly.
Let’s create such a CronJob now. After all, at the end of the day we greatly prefer to have an empty ToDo list, and the easiest way to achieve this is … to simply delete its contents (well, not really, but let’s go with this now).
We have prepared a corresponding template for you:
cat postgres-cleanup.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: postgresdb-cleanup
spec:
successfulJobsHistoryLimit: 5
schedule: "*/2 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- image: postgres
name: postgresdb-cleanup
command:
- bash
- -c
- cd && echo "*:*:*:*:$PGPASS" > .pgpass && chmod 600 .pgpass && psql --host=postgresdb --command="delete from todo"
env:
- name: PGUSER
valueFrom:
secretKeyRef:
name: db-security
key: db.user.name
- name: PGPASS
valueFrom:
secretKeyRef:
name: db-security
key: db.user.password
- name: PGDATABASE
valueFrom:
configMapKeyRef:
name: postgres-config
key: postgres.db.name
restartPolicy: OnFailureSo let’s just apply this file now:
kubectl apply -f postgres-cleanup.yaml
and directly check the state:
kubectl get cronjobs
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
postgresdb-cleanup */2 * * * * False 0 <none> 3sMilestone: K8S/STORAGE/POSTGRES-CLEANUP
OK, the CronJob didn’t have any chance to run yet, so let’s wait a bit and watch our Jobs:
kubectl get jobs --watch
NAME COMPLETIONS DURATION AGE
postgresdb-import 1/1 4s 17m
postgresdb-cleanup-28357184 0/1 0s
postgresdb-cleanup-28357184 0/1 0s 0s
postgresdb-cleanup-28357184 0/1 4s 4s
postgresdb-cleanup-28357184 1/1 4s 4s
Ctrl+CThe postgresdb-import was already listed when we executed the command, and the various postgresdb-cleanup-… were added later on. Looking good so far, apparently the Job was now indeed executed.
By the way, the number suffix is just the execution start time in minutes passed since the Unix epoch:
date -d@$((28357184 * 60))
Fri Dec 1 12:44:00 CET 2023(Formerly it had been the seconds since the Unix epoch, but that didn’t make all too much sense given that such a cronjob execution scheduling has a minimum granularity of one minute.)
Let’s confirm CronJob execution:
kubectl get cronjob postgresdb-cleanup
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
postgresdb-cleanup */2 * * * * False 0 78s 2m41sand
kubectl logs job/postgresdb-cleanup-<timestamp>
DELETE 4as well as
curl <LoadBalancer-IP-todobackend>:8080/todos/; echo
e.g.
curl 20.82.83.63:8080/todos/; echo
[]Yes, indeed all empty now, and we can relax: nothing to be done anymore, at least according to our todo list.
And after a while we see several executions, a number of up to successfulJobsHistoryLimit as defined above are kept:
kubectl get jobs
NAME COMPLETIONS DURATION AGE
postgresdb-cleanup-28357184 1/1 5s 6m40s
postgresdb-cleanup-28357186 1/1 5s 4m40s
postgresdb-cleanup-28357188 1/1 4s 2m49s
postgresdb-cleanup-28357190 1/1 4s 49s
postgresdb-import 1/1 4s 25mBut letting this jobs run every two minutes is a bit excessive. After all, we just wanted to clear the list by the end of the day, so let’s relax the schedule a bit:
kubectl patch cronjobs postgresdb-cleanup --patch '{ "spec": { "schedule": "0 17 * * *" } }'
Of course, this was just for the purposes if illustration, and a more sensible use of this would have been to make sure certain entries (e.g. “Feed the cat”) were added each day, so feel free to just delete the cronjob instead:
kubectl delete cronjob postgresdb-cleanup
Milestone: K8S/STORAGE/POSTGRES-CLEANUP-RM
Exercise - Consider storage risks
So, we have introduced persistent state into our application. And that state is referenced statically, leading to certain issues. Let’s imagine we scale up the postgresdb deployment, adding further replica pods. What would happen?
We can address these issues by using StatefulSets , as we investigate now in the next chapter.
Info
One last word of warning about storage here, though: please note that Kubernetes will try its best to ensure that no defined state gets lost, ever. Among other things this means that all PersistentVolumes that have ever been claimed by a PVC might need to be recycled manually, depending on your corresponding PV ReclaimPolicy.